Mini-spire: a fast Slay the Spire RL environment in C++
I remember reading about Claude playing Pokemon Red when Sonnet 3.7 was released and thinking to myself "this is the wrong way to 'solve' Pokemon". An LLM taking pixel images as input and spitting out Gameboy actions seemed too slow and wasteful from a compute perspective. Obviously, I don't think Pokemon Red, a game many of us remember from our childhoods, is a hard-to-solve problem. Nor was Anthropic trying to necessarily beat the game, they were just using it as a benchmark to demonstrate the gains in performance Sonnet 3.7 showed over previous iterations. However, I always thought for a game like Pokemon, which revolves around battling (a zero-sum game) and a static action space (Gameboy buttons), Reinforcement Learning would be the best tool for the job. Little did I know at the exact same time, David Rubinstein and co. released PokeRL, in which they beat Pokemon Red with nothing but pure Deep RL (no LLMs required). While their approach did take some incredible engineering (I highly recommend reading the full post) and they exposed additional higher-level information for the agent's observations, it was inspiring to see a < 10 million parameter policy trained with PPO could complete a game that challenged a younger me and is still being played today for nostalgia or personal challenge (e.g. Nuzlockes).
Around the same time as I was reading the PokeRL article, Slay the Spire 2 launched in early access, and as such, I once again fell in love with the roguelike deck-building game that, similar to Pokemon, revolves around a sequence of zero-sum battles with hundreds of microdecisions to make along the way in order to successfully beat the game. As such, I wondered to myself if RL environments existed for Slay the Spire (the original or its sequel) and if anyone had produced a similar effort to PokeRL. Given the original game is so modder-friendly, I wasn't surprised to see projects like gym-sts which wraps the actual game (requires a full copy of STS as a .jar file) with a Gymnasium environment. However, given I do all of my development work on a 2020 M1 MacBook Pro, I was hoping to find a more efficient implementation that I could feasibly use to train an agent on. That's when I came across Miles Oram's C++ implementation which implemented the full game with the Ironclad character using only information from the game's wiki (and I assume personal experience playing the game) and trained a DQN model to beat the game. Miles used a similar approach to what I was imagining, dividing the game into different tasks (e.g. battling, picking which room to go to next) and then training different models to accomplish each singular task. Yet, when I went to go fork the code, I saw that there was little to no documentation and no user-friendly environment API (e.g. Gymnasium-style), which makes sense given it was a personal pet project. However, with that, and the desire to train agents on characters other than Ironclad, mini-spire was born.
Mini-spire is a C+±based recreation of Slay the Spire with python bindings that expose a Gymnasium-style API for training and benchmarking RL agents. At the time of writing, it can currently only play a single fight with Ironclad against the Jaw Worm, but it was built with modularity and extensibility in mind so that adding other, more challenging enemies will be trivial. The same way Miles divided their project into different tasks, mini-spire is focused on just combat to start, with adding map generation and persisting state between fights being a long-tail goal.
Observation Space. The observation space is a flat 45-float vector comprised of the following:
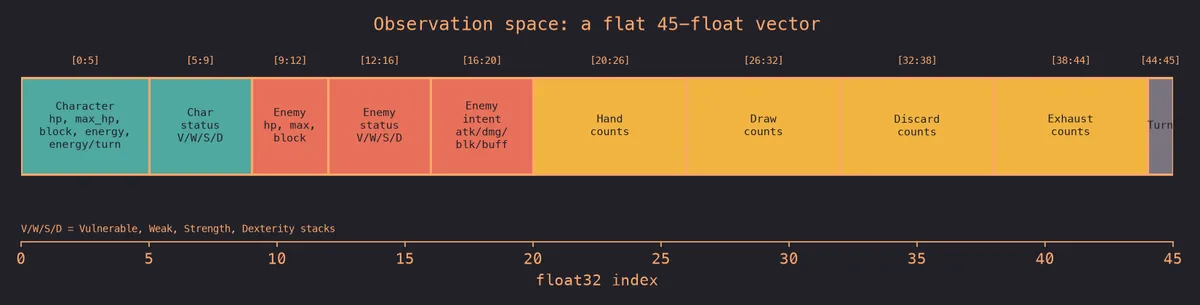
You'll notice that the hand observation utilizes one index per card (e.g. if I have three strikes and two defends, my vector looks like [3, 2, 0, 0, 0, 0]) and that the size is dependent on the number of unique cards in the deck. This approach simplifies the observation space by not having to worry about hand ordering (if I have a strike in my hand, it doesn't matter if its card #1 or card #3) and instead enables the agent to learn what having multiple strikes (higher possible damage output) or multiple defends (higher possible block this turn) means semantically. I also chose to stick with Ironclad's starter deck (and its upgraded variants) to start, but eventually, the vector will be size 2 * N + C where N is the size of Ironclad's total card pool and C is the number of possible curses, dazed, etc. The draw, discard, and exhaust piles follow the same approach, as human players also cannot see which card will be drawn next, but rather just the entire pool available to them.
Action Space. The action space, similar to representing the character's hand, is a discrete set of seven actions, where each entry represents playing a different card as well as an "end turn" action, which is always available to the character, regardless of their energy level:
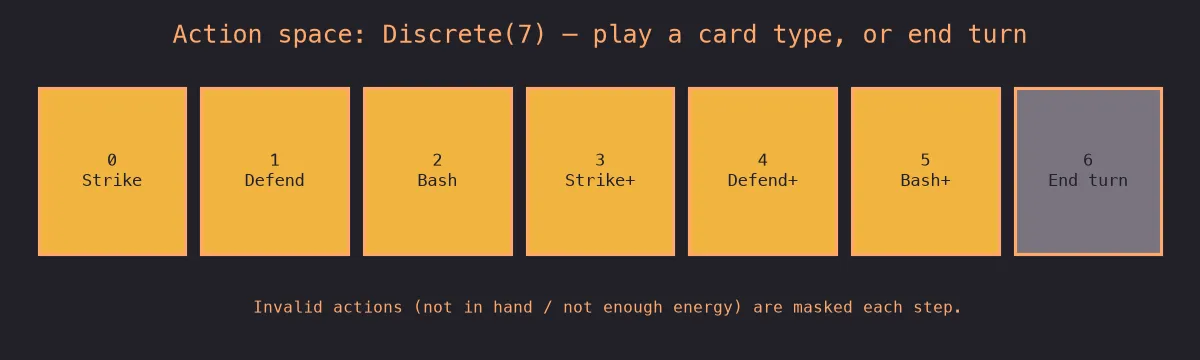
The environment makes heavy usage of action masking so that any card that isn't currently in the character's hand or is too expensive to play, is an invalid action. Similar to the observation space, the action space grows with the cards available to the character/environment.
Reward Function. The reward function for the environment is by default +1/-1 for winning or losing the fight and 0 at all other timesteps. However, with extensibility and implementing the full game in mind, there's an optional additional reward of the normalized health remaining (current_hp / max_hp) that is added to the reward for winning and is controlled by a scalar coefficient to determine its contribution to the total reward (e.g. 0.0 --> only use +1/-1, 1.0 --> add the full normalized health remaining). While reward shaping can be finicky and influence the agent's learning, it's generally accepted that having higher HP at the end of fights in Slay the Spire puts you in a better position for the following fight(s).
Throughput and Testing. To test the environment, I implemented a ~15k-parameter maskable PPO agent from the StableBaselines3 library and trained it for 1 million timesteps. As a comparison, a random policy agent achieves a win rate of ~52%, which is expected given that the character starts out with full HP against one of the easiest enemies in the game. That said, within ~50k training steps the agent was winning ~90% of fights on all runs, and by ~80k training steps it had stopped losing entirely.
Using the python bindings, the environment can process ~145k steps/sec with a single environment on my M1 Macbook Pro's CPU. Actually training the agent dropped the throughput to ~4,300 environment steps/sec, which seems low, but results in around four minutes to train an agent for 1 million timesteps.
Usage. Even though the environment itself is implemented in C++, I utilized python bindings to expose a Gymnasium environment API that any RL developer will find familiar:
from minispire.env import MinispireEnv
env = MinispireEnv()
obs, info = env.reset(seed=0)
mask = env.action_masks()
obs, reward, terminated, truncated, info = env.step(action)
While I only measured the throughput by averaging the step rate across a few runs, I've already realized the gains of implementing this environment in C++ from scratch. While I'm sure my laptop could handle a more traditional Gymnasium wrapper like gym-sts, being able to fully train an agent in under five minutes (realistically reaching 100% win rate in under 1 minute) on a six year-old laptop is a testament to removing the RL-environment bottleneck. As I continue working on the environment by adding additional enemies, sequential fights, and even multiple acts, the only bottleneck I'll face will be training the agent's networks, which is much better suited for a GPU anyways. If you're curious about the code or learning more about the environment, feel free to check it out on GitHub.